
|
|

GTX 280

Here is a chart that should give you better understanding how massive and complex the GTX 280 is compared to an ordinary CPU.
| Intel Core 2 QX9650 | GeForce GTX 280 | |
| Transistors | 820 million | 1.4 billion |
| Processor Clock | 3 GHz | 1296 MHz |
| Cores | 4 | 240 |
| Cache/shared Memory | 6 MB x 2 | 16 KB x 30 |
| Threads executer per clock | 4 | 240 |
| Hardware Threads in operation | 4 | 30720 |
| Peak Gigaflops | 96 | 933 |
| Memory Controller | Off-die | Internal 8 x 64-bit |
| Memory bandwidth | 12.8 GB/s | 141.7 GB/s |
Those 1.4 billion transistors form 240 shader processors and 80 texture processors. Combine that with 1 GB of frame buffer and you have one hell of a parallel computing unit. With the industry standard and open CUDA technology this power can be put to real use even outside the gaming environment.
Parallel processing
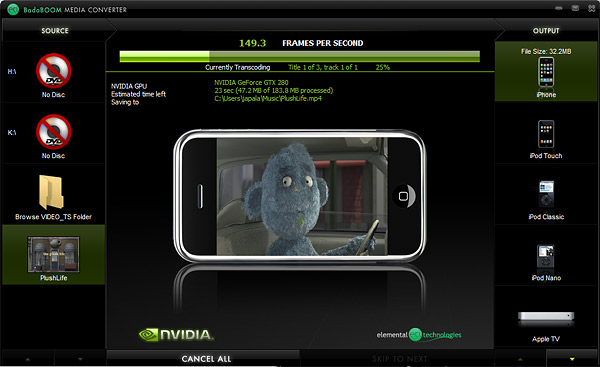
Paralled processing power of the GT200 can be easily demonstrated with the new RapidHD transcoding program Badaboom from the Elemental Technologies. With CUDA technology the conversion time can be cut down by 10-18 times from what it would take from the most powerfull CPU. With this demo clip, 149.3 frames per second when transcoding to H.264 gives you some indication what the new technology offers.
HybridPower technology
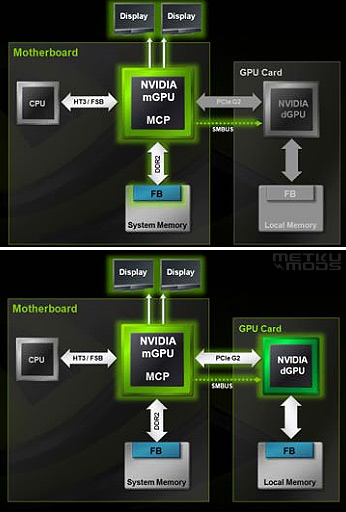
-
Four operating modes:
- Idle/2D power mode (approx 25 W)
- Blu-ray DVD playback mode (approx 35 W)
- Full 3D performance mode (varies - worst case TDP 236 W)
- HybridPower mode (effectively 0 W)
When using a HybridPower-capable nForce motherboard, for example 780a and 790 chipset based ones, the system can automatically shut down the GTX200 GPU and use the motherboard's GPU. When the system sees the need for read 3D power, the GPU on the card is brough back online automatically and without disturbing the normal operation of the system.
HybridPower works by sending the output of the discrete GPU through the output connector on the motherboard. This allows the system to use both GPUs as it sees fit without physically changing the connector.
NVIDIA PhysX
You may have already heard about this and the Futuremark's Vantage. In the past PhysX was either simulated on the CPU or handled by a PhysX add-on card, made by Ageia. NVIDIA bought Ageia and incorporated the PhysX calculation to their GPU and boy what a mess that made for benchmarkers. Parallel architecture made the calculations so fast that it boosted up the score on the Vantage and naturally people started to accuse NVIDIA for cheating. Now that we know the calculations are handled by the GPU instead of the slower CPU and adjust our views and ways of the past a bit, we see that this is only a good thing and that NVIDIA was an innovator and not a cheater. We'll talk more about this when we get to the benchmarks.
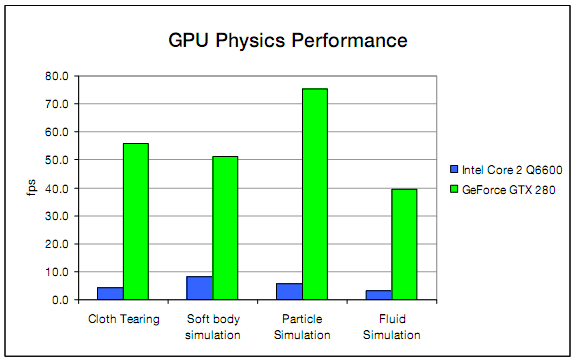
The table shows common problems like cloth, soft bodies and fluid simulation. The GPU is on average is 11× faster than a quad core CPU on a preliminary implementation of the PhysX. engine on the GPU.
| | Pages: 1 2 3 4 5 6 7 | |
 Content in english!
Content in english! Sisältö suomeksi!
Sisältö suomeksi!